The Audio Alchemy Log: A Researcher's Journey from Rhythm Games to Scalable Audio Systems
– ArtXTech
A Researcher’s Journey from Rhythm Games to Scalable Audio Systems
To be honest, this whole thing is DrumMania’s fault. What started as a simple desire to play a rhythm game at home spiraled into a years-taking descent into hardware hacking, signal processing, and crying over Python dependencies. This isn’t just a portfolio; it’s a log of how I turned “pissed off” into a scalable audio pipeline.
 Caption: It all started with a classic rhythm game
Caption: It all started with a classic rhythm game
TL;DR: Key Competencies Demonstrated in This Log
- Hardware Hacking: Built a MegaDrum from scratch because off-the-shelf gear was rubbish. (Then watched it literally melt. Fun times.)
- Advanced Audio Craft: Deconstructed and remastered commercial tracks, demonstrating a deep understanding of audio structure and emotional impact.
- Systems Architecture: Built an end-to-end Audio-to-Data pipeline using Python, Librosa, and MIDI to bypass “soul-crushing” manual charting.
- Applied Data Science: Conducted academic research comparing ML models (CNN vs. Feature Engineering) for audio classification, proving a data-driven approach to curation.
- Human-in-the-Loop Philosophy: Validated that automated outputs require expert human oversight for quality assurance and creative refinement-a core principle for any scalable creative platform. Remastered K-Pop into Shoegaze because Gen AI (Suno/Udio) sounds like digital weathering and I reckon I can do it better myself.
1. The Trigger: When Obsession Meets Engineering
It all started with a rhythm game called DrumMania, my obsession.
My initial motivation was simple: I wanted to play the game perfectly at home. My personal goal to perfectly play the arcade game ‘DTX mania’ and ‘Clone Hero’ at home quickly evolved into a technical challenge. Technical constraints stood in the way. This question led me down a rabbit hole. What began as a hobby of repairing broken drum kits spiralled into a deep dive into hardware hacking. I found myself building a MegaDrum controller from scratch to bypass the limitations of off-the-shelf hardware.
But hardware is a cruel mistress. My custom circuit eventually fried itself—properly melted the brain of the module. Then my Medeli 402 started sending ghost notes like a haunted radio.
My journey began in earnest when I decided to create custom charts for a similar game, ‘Clone Hero’. I quickly realised the manual process of listening and transcribing was incredibly tedious and prone to error. This was a classic data extraction problem, and I was determined to find a more elegant solution.
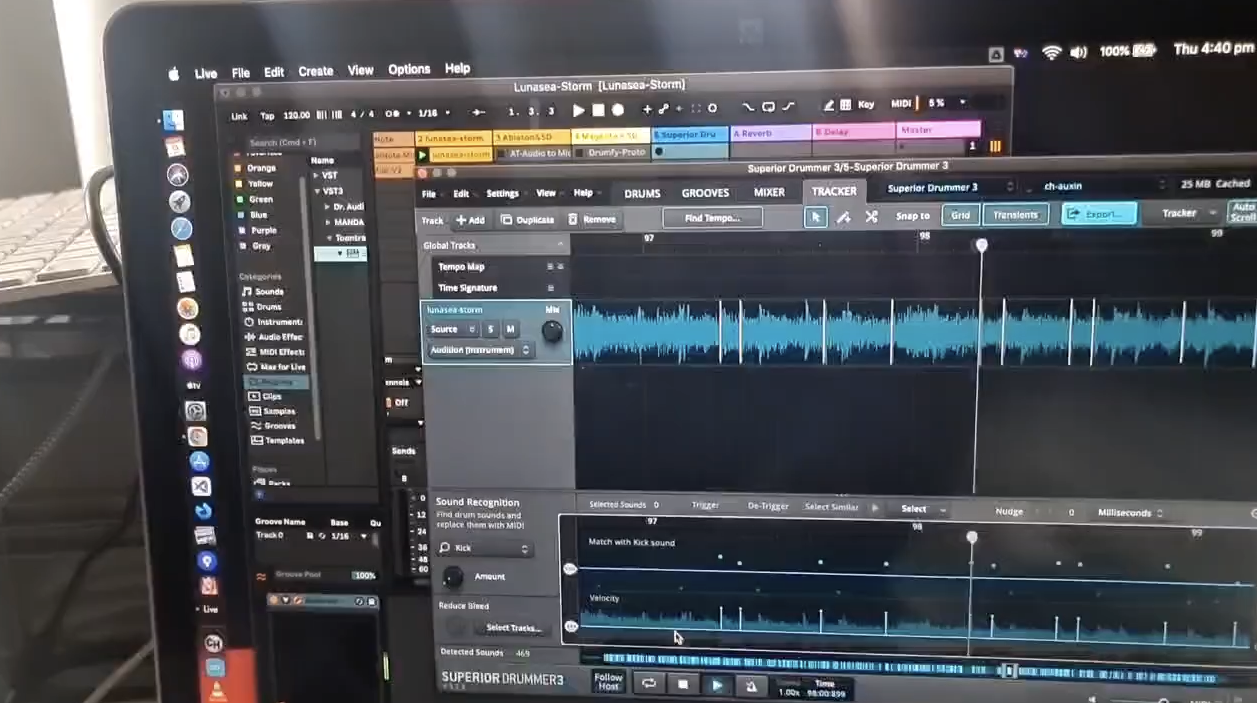 Caption: Analysing drum waveforms in Superior Drummer to identify kick and snare transients.
Caption: Analysing drum waveforms in Superior Drummer to identify kick and snare transients.
The path was anything but smooth. My initial attempts at full automation were met with frustrating setbacks, mostly wrestling with Python dependencies. The period between November and December 2023 was a deep dive into the practical realities of audio data, battling with tools like TuxGuitar and Audacity, and painstakingly syncing MIDI files by eye and ear. It was a crucial lesson: before you can automate, you must deeply understand the manual craft.
But hardware was just the entry point. To generate infinite play data for my sessions, I needed to understand the software side. This necessity pushed me to teach myself DAW workflows (Logic Pro), VSTs, and eventually, Python for audio analysis.
This wasn’t just a hobby; it was a self-directed curriculum. To get the data I wanted, I had to teach myself the fundamentals of digital audio, signal processing, and eventually, data science.
2. The Process: Reverse-Engineering the Beat
Phase 1: The Hardware & Data Extraction
This required analysing kick and snare patterns from raw audio files via Superior Drummer VST.
I envisioned a seamless, automated pipeline using Machine Learning. I tried to automate drum charting for Clone Hero. I envisioned a world where I’d feed the track track and get a perfect MIDI file out. Reality check: It was a total shambles. I spent November 2023 wrestling with Python environments and OCR tools that couldn’t tell a snare from a hole in the ground.
 Attempting TAB OCR to read drum tabs from sheet music.
Attempting TAB OCR to read drum tabs from sheet music.
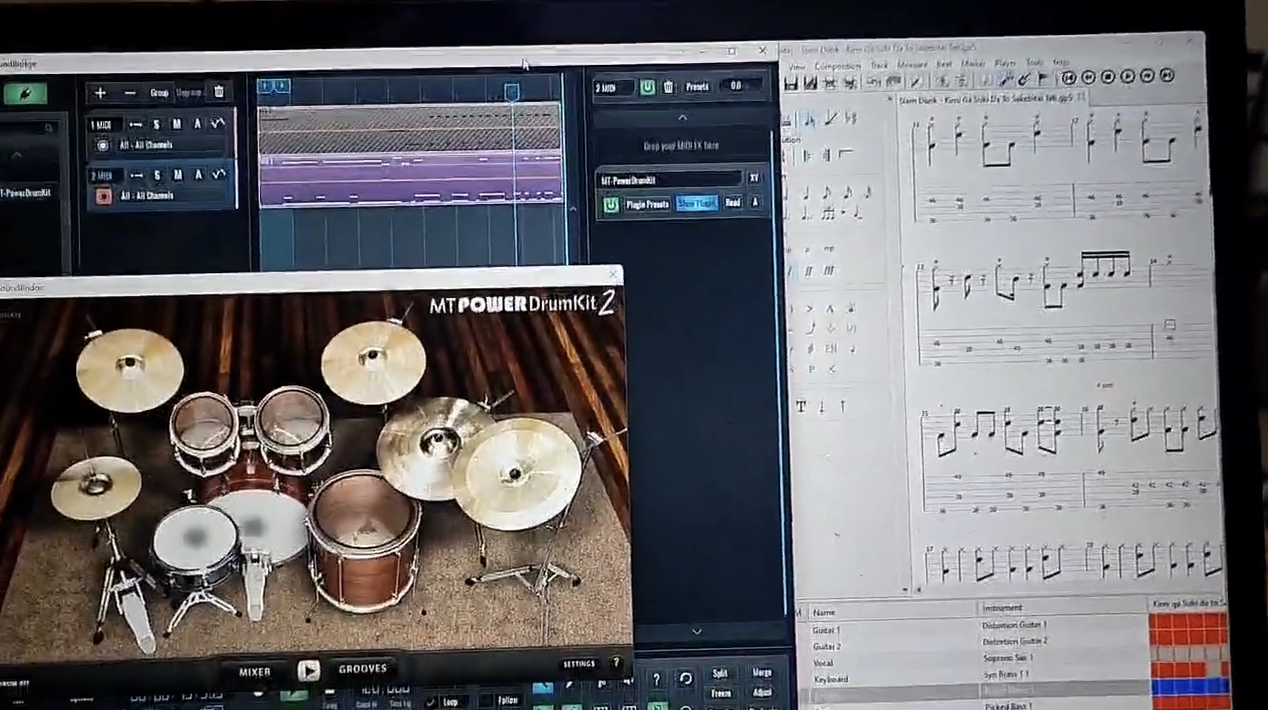 Extracting drum MIDI from Guitar Pro tabs and attempting playback through a VST.
Extracting drum MIDI from Guitar Pro tabs and attempting playback through a VST.
The journey wasn’t linear. I dived into audio analysis frameworks, hoping to automate the tedious process of charting.
 Screenshot of a Streamlit app **analysing** drum parts by extracting audio from YouTube links.
Screenshot of a Streamlit app **analysing** drum parts by extracting audio from YouTube links.
I finally managed to extract timestamps into a CSV and convert that to MIDI. I had a “proper nerdgasm” for about five seconds—until I realized the source was 108 BPM and my MIDI was dragging at 94 BPM. Absolute rubbish.
Phase 2: The Reality of “Trial and Error”
The reality was far from the dream. I faced significant hurdles.
- Dependency Hell: Wrestling with Python library conflicts and environment setups.
- OCR Limitations: Attempts to use OCR on drum tabs failed to yield accurate MIDI data.
- Sync Issues: Even when data was extracted, the MIDI timing often drifted from the audio grid.
I spent months between late 2023 and early 2024 dealing with these issues; manually adjusting sync in Audacity, tweaking MIDI in Logic Pro, and cross-referencing with TuxGuitar. It was a rigorous period of R&D that felt like hitting a wall, but it was building a crucial foundation in data integrity and signal processing.
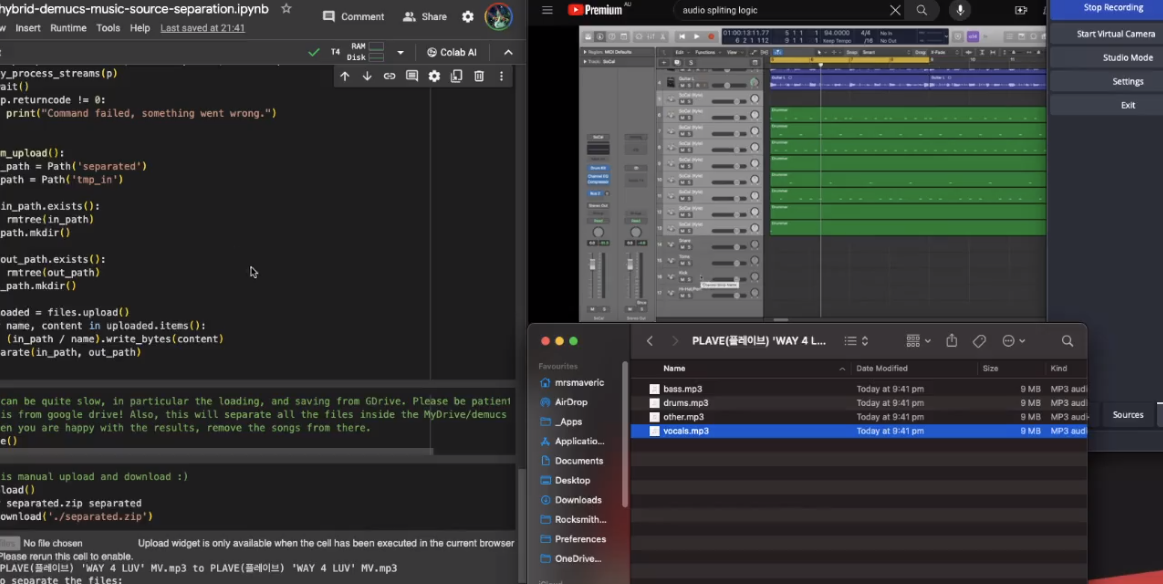 Experiments with Demucs for stem separation and time-stamping trigger attacks.
Experiments with Demucs for stem separation and time-stamping trigger attacks.
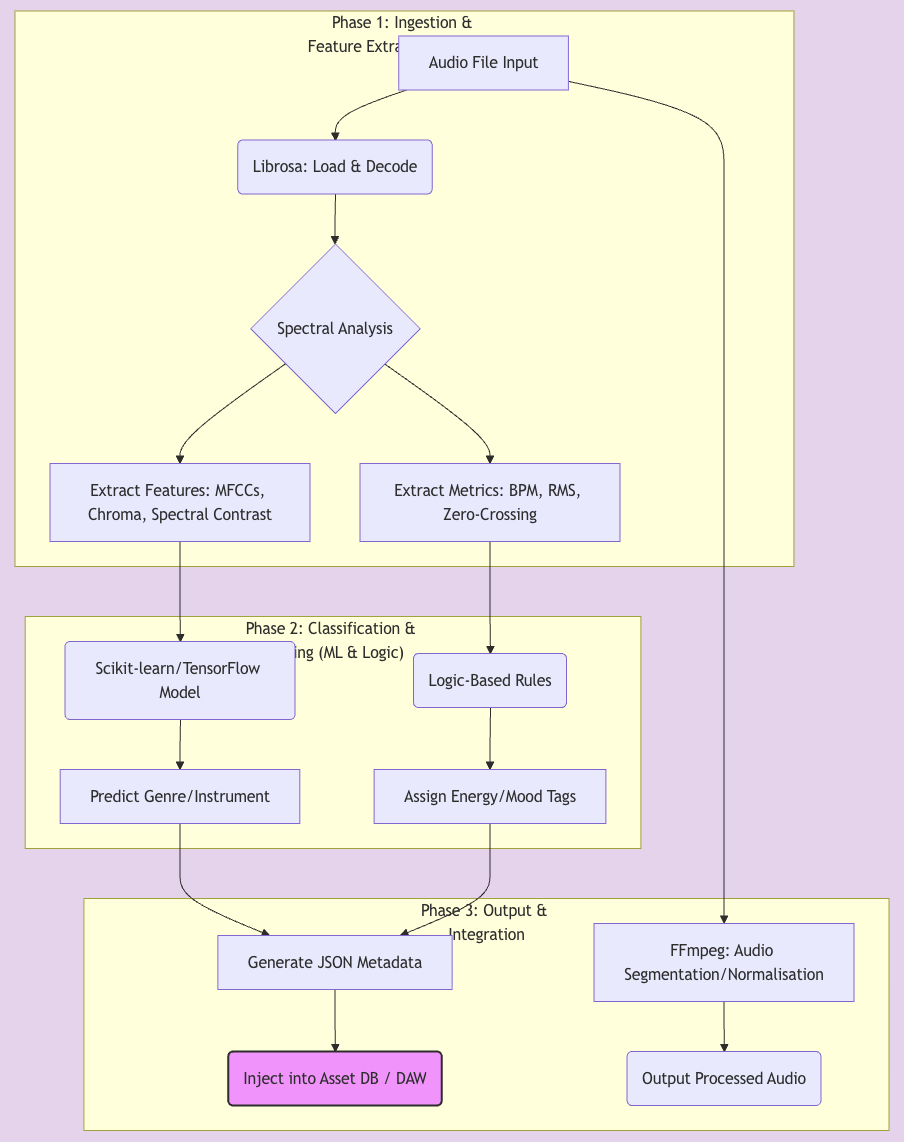
I tried to build something far more valuable in the process: the ability to design and construct an ‘end-to-end system’ to solve a complex problem. The Audio-to-Data Pipeline. A system designed to bridge the gap between unstructured audio and structured, interactive data.
The process involved:
- Source Separation: Using frameworks like Demucs to isolate drum tracks from a source link.
- Transient Detection: Applying models in a Google Colab environment to analyse the audio and export timestamps for percussive hits.
- Data Transformation: Writing a Python script with the Librosa library to convert these timestamps into a structured MIDI file.
- Human-in-the-Loop Refinement: Importing the generated MIDI into Logic Pro to manually correct timing nuances and velocity details that the model missed—a critical QA step.
- Final Conversion: Using Tone.js to transform the polished MIDI file into the game-specific chart format.
A significant challenge was correcting the BPM discrepancies between the source audio and the generated MIDI-a practical problem in data integrity that required both code-based solutions and a musician’s ear to resolve.
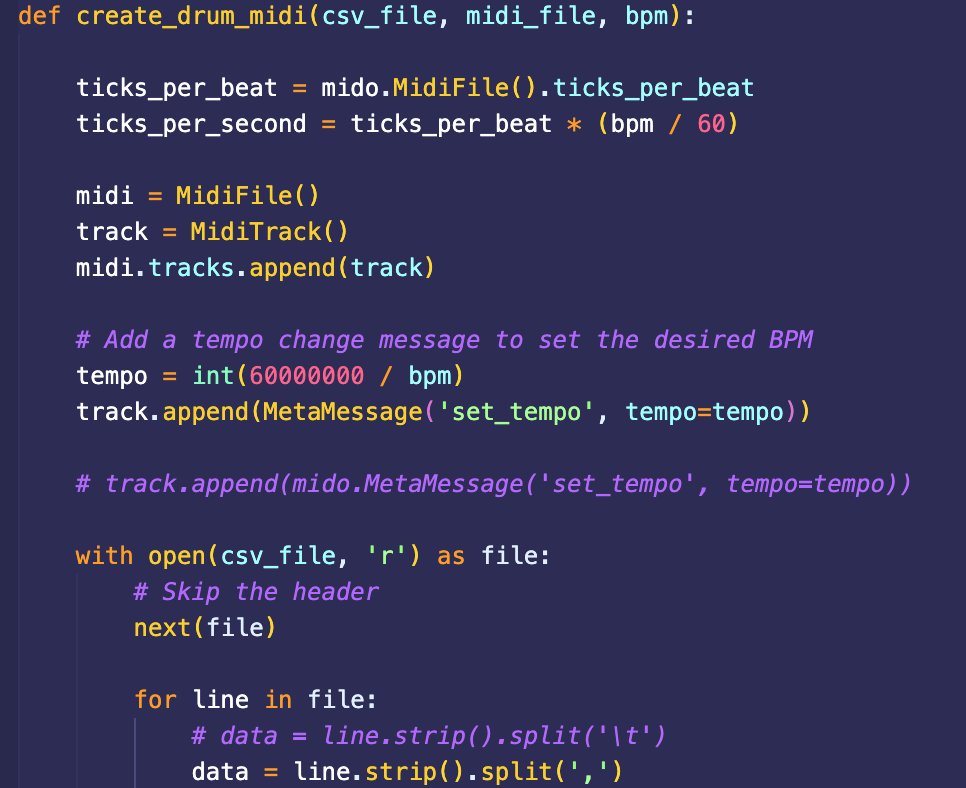 The csv file extraction was a no-go, so I wrote some code to convert CSV to MIDI files instead.
The csv file extraction was a no-go, so I wrote some code to convert CSV to MIDI files instead.
So, the last time we spoke, I’d wrestled Python into submission and built a script that could take a boring-arse CSV file full of data and transmute it into a living, breathing MIDI file. The proof of the pudding? I got the bloody thing working as a playable chart in Clone Hero. A technical victory. For a moment, I felt like a god. I’d stared into the abyss of audio data and the abyss blinked first.
This whole painstaking process, this deep dive into the guts of sound design, was a massive level-up. I wasn’t just mucking around anymore; I was architecting systems, anticipating errors, thinking like a proper music producer.
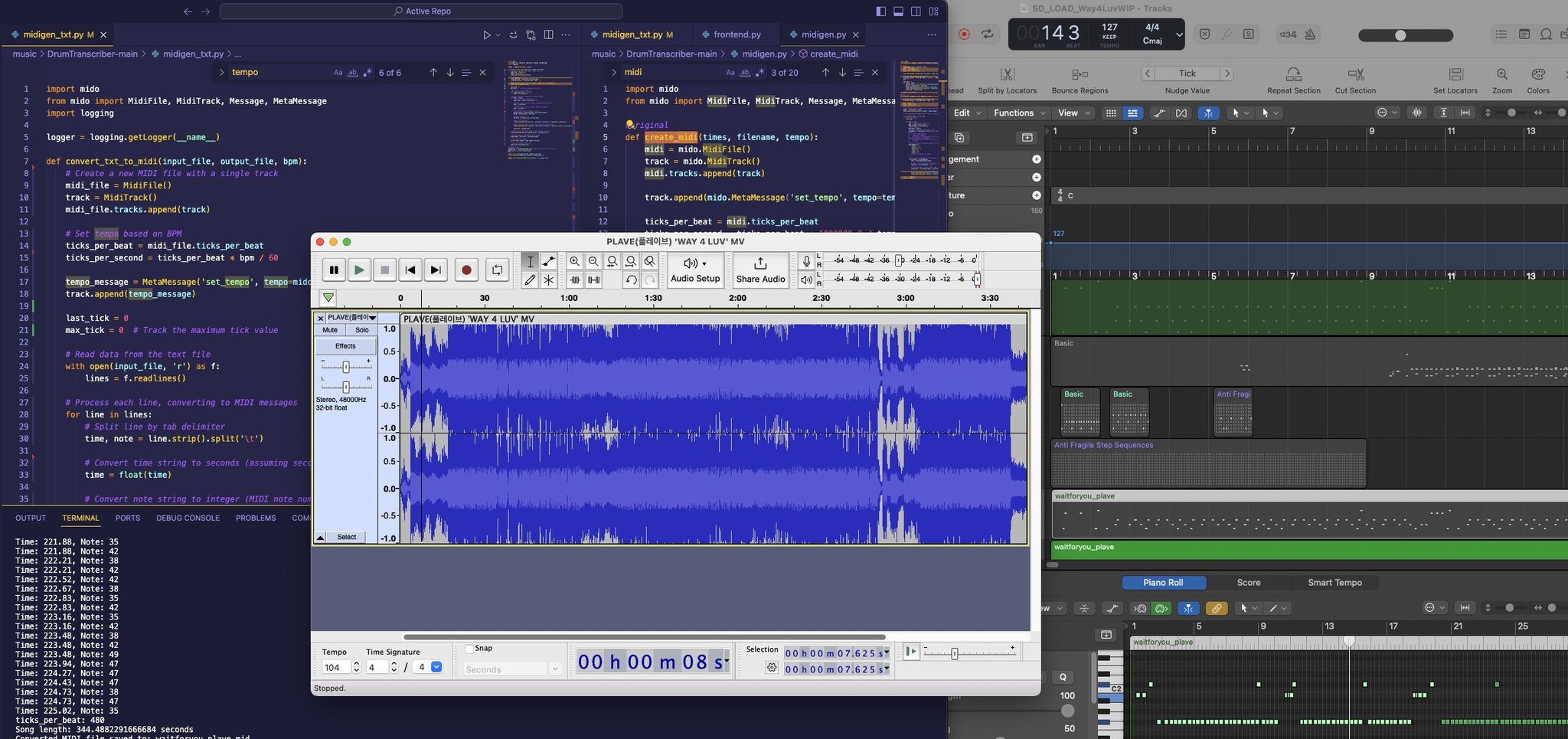 Audacity was easier for sorting out formatting issues and final edits, so this shows me using Logic and Audacity side-by-side.
Audacity was easier for sorting out formatting issues and final edits, so this shows me using Logic and Audacity side-by-side.
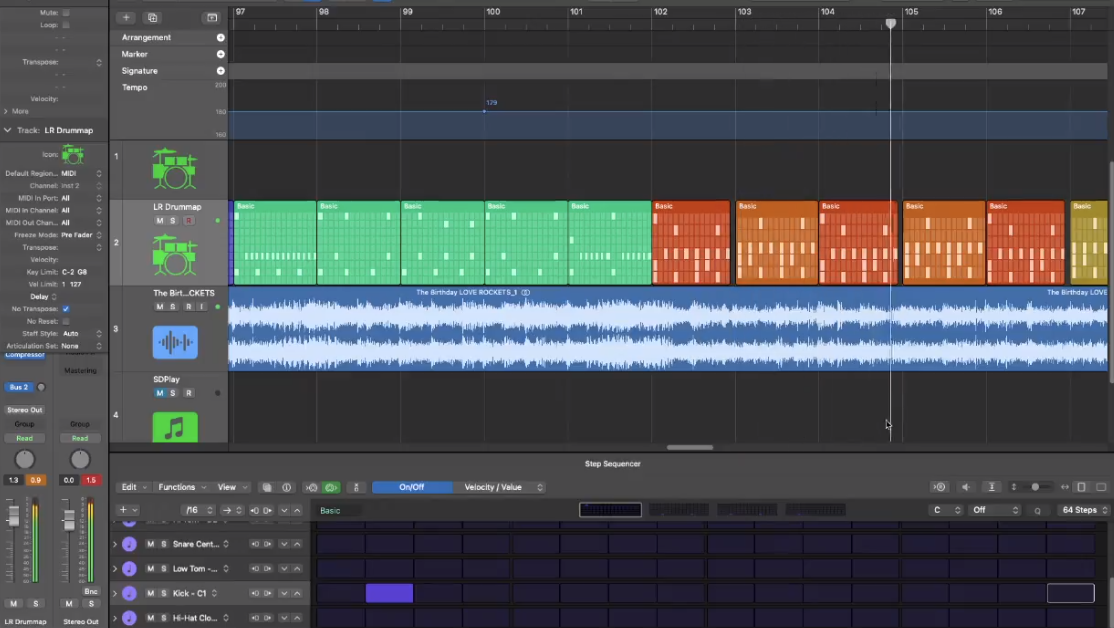 Back to manual sequencing, after tasting bitterness of result out of generative model outputs
Back to manual sequencing, after tasting bitterness of result out of generative model outputs
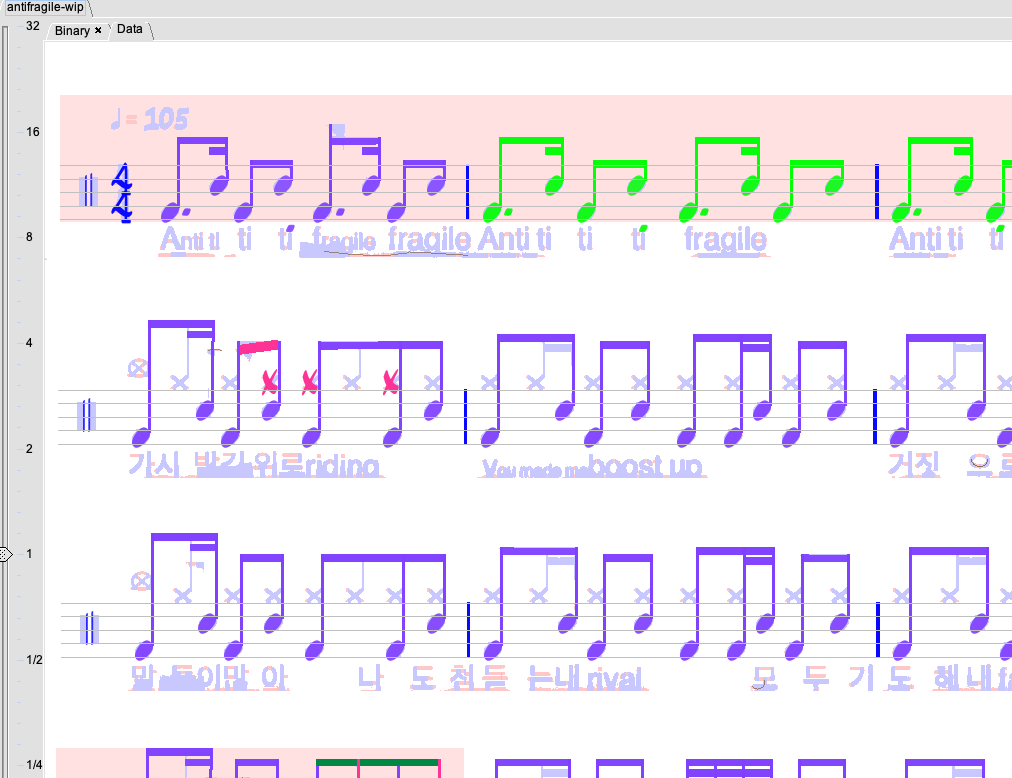
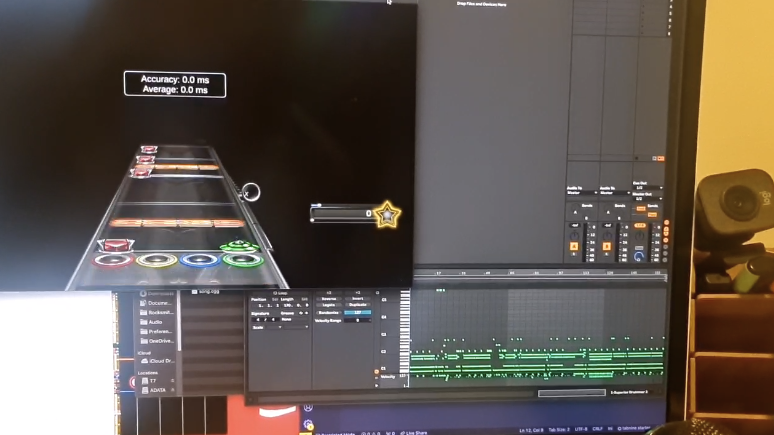 Screenshot of a sample converted into a Clone Hero chart using the MIDI file I finally put together.
Screenshot of a sample converted into a Clone Hero chart using the MIDI file I finally put together.
And yeah, the workflow was a complete shambles. A Frankenstein’s monster of Logic Pro for the heavy lifting, Audacity for the quick and dirty edits (because sometimes its old-school simplicity is just faster, don’t argue), and my own custom scripts holding it all together with digital sticky tape.
So that was it. My grand crusade to analyse drum sounds and build a janky-but-functional Clone Hero chart was done. I could finally kick back, shred some drums, and wrap up 2024 with a win.
…would’ve been a nice, happy ending, wouldn’t it?
Yeah, well, pull the other one, it’s got bells on.
3. The Insight: Reframing Failure into Methodology
Because here’s the thing about this line of work. Just when you reckon you’re over one mountain, you find out you’re just at the bottom of a bloody bigger one.
Playing the charts that my model generated… it was a nightmare. On paper, the MIDI file was flawless. Every note was where it should be. Every hit was on the grid. But when you actually played it, it was grating. The groove, the beat, the very soul of the rhythm was subtly, horribly, unforgivably off. It was the uncanny valley of funk.
Every kick and snare landed with the cold, dead precision of a machine that understands timing but has zero concept of time. There was no push, no pull, no human swagger. It was technically perfect and musically sterile. It was like listening to a spreadsheet. My ML workflow system, for all its cleverness, had produced a beat with all the groove of a tax return.
My second attempt involved Demucs and Keras to achieve full automation; and I hate to admit - it failed harshly. While the results improved, they were not perfect. The AI could separate stems, but it lacked the nuance to interpret “groove” or subtle ghost notes accurately.
The pipeline worked, but a key bottleneck remained: “How can I classify the sounds of ‘kicks’ versus ‘snares’ more quickly, consistently, and scalably?”
This question became the central thesis of my postgraduate research project in the latter half of 2025. This insight became the cornerstone of my postgraduate research later that year.
Validation: Classic Models vs. Deep Learning
The Hypothesis: For a specific domain (e.g., acoustic drums), a classic machine learning model using domain-expert-driven Feature Engineering would provide more efficient and explainable results than a monolithic black-box model (like a CNN).
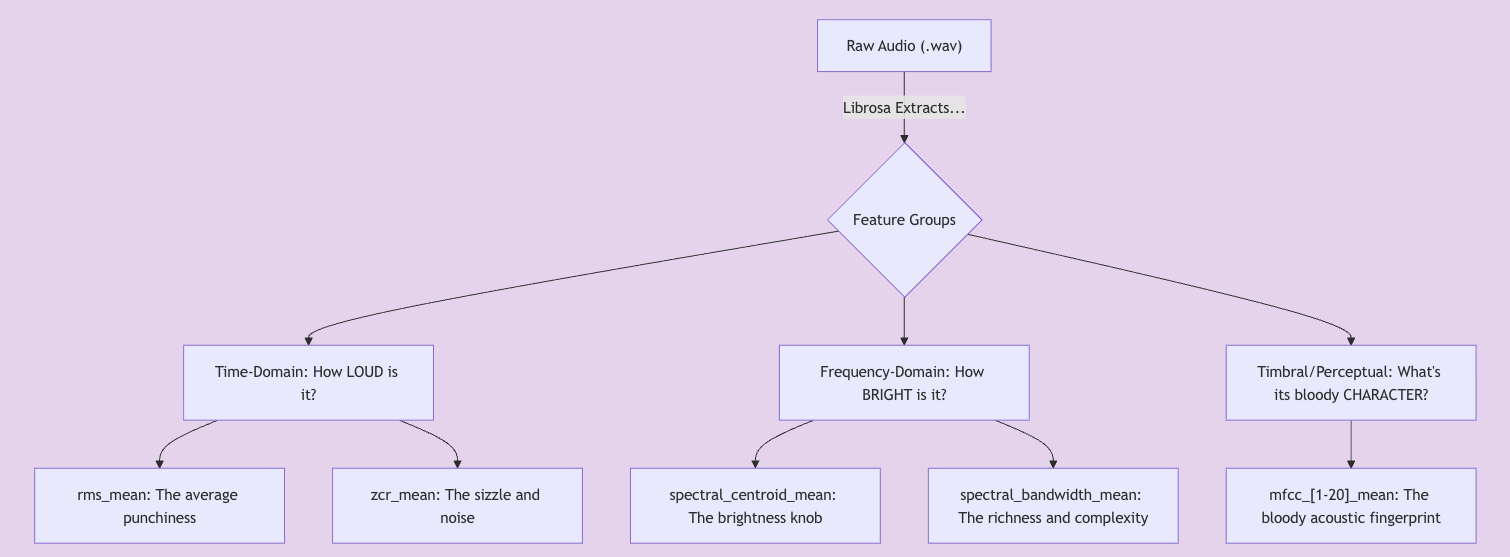
In a subsequent project regarding image and audio classification, I tested two approaches.
- Feature Engineering: Extracting the ‘digital fingerprint’ of each sound (MFCCs, Spectral Centroid, Zero-Crossing Rate) to convert its unique acoustic properties into data a classic model could understand.
- Deep Learning (CNN): Using a visual representation of the sound (a spectrogram) as an image, allowing a Convolutional Neural Network to learn and classify patterns on its own.
The Result: The classic, feature-engineering-based models often outperformed complex CNNs in distinguishing subtle acoustic drum sounds (with 90%+ accuracy). This proved that domain knowledge (understanding the audio) is just as critical as the algorithm itself.
Ultimately, the classic models, informed by feature engineering, validated the hypothesis This result suggests that for building a reliable architecture to assist or automate curation, the most effective system is one that integrates expert domain knowledge into its very design. This ‘Human-in-the-Loop’ approach is essential for maintaining quality at scale.
Click here for the Full Research Summary: CNN vs. Classic Models for Drum Sound Classification
4. The Pivot: From Analysis to Creation
The Sound Design Gateway
While processing hundreds of audio samples for my datasets, I inadvertently deepened my understanding of Sound Design. The tedious work of manually cutting and labelling samples; what I jokingly call “manual data cleaning”-forced me to master the DAW environment.
Buuuuuuut…
I got tired of “analysing” and wanted to “create.” I checked out Suno and Udio, thinking maybe they’d replaced me.
The Verdict: Absolute dross. As soon as you put on a decent pair of cans (headphones), I hear the “digital weathering.” It’s audio soup. I’d rather spend hours in Melodyne or Flex Pitch doing it manually than use those “one-click” toys. I haven’t used Studio premium version from Sudo yet. However, my expectation got already heavily smacked down and my ears already got spoiled by Apple’s high quality music library loop sets.
I began to ask: If I can analyse this data, why can’t I perform it?
I am now synthesising these technical skills into creative output. My recent work involves remixing K-Pop tracks to fit a retro-rock aesthetic, applying the signal processing knowledge I gained from my engineering days.
I took ‘Your Idol’ by Saja boys(Yes, from K-pop demon hunters) and gave them the “Industrial Garage” treatment. I wanted sharp guitars and heavy, concert-hall drums, not the thin EDM textures.
Caption: A 30-second comparison of the original track vs. my remastered Shoegaze version.Soooooo, here we are. My poor guitar/bass/drum plays sprinkled top of EQ-edits a bit, thanks to Logic Pro’s massive plug-in sets to trim my shit playing part. That’s how re-master version is made. Tadaaaa. Now I can enjoy listening to this and imagine to be in the concert hall with live session band behind.
By the way, this is only for my private use. So this re-mastered version only plays on my personal device.
Current Project: The K-Pop Shoegaze Fusion
I am currently taking the other songs in treatment. I wanted sharp guitars and heavy, concert-hall drums, not the thin EDM textures. I’m currently “Frankenstein-ing” a workflow that connects Remotion(React+Vite+WebGL), TouchDesigner, and the Canvas API to make M/V for these tracks visually.
5. Current State: The Convergence
Epilogue: From Analysis to Artistry
Ultimately, this technical and academic exploration serves one purpose: to create better creative experiences. For me, data analysis and audio production are two sides of the same coin.
Through this journey, I’ve learned to operate as someone who uses the fire of technology to refine the raw ore of audio, applies the reagent of data to analyse its essence, and ultimately, creates new experiences that resonate with people.
What’s Next? I am currently developing a workflow that combines Audio/MIDI APIs with the Canvas API. The goal is to use WebGL and 2D animation to create dynamic motion graphics that react in real-time to tempo and beat triggers-a true convergence of my coding background and artistic vision. This led to a desire to record a one-person band cover. I envisioned a system connecting Node.js as a central hub, sending MIDI to Logic Pro, triggering visuals in TouchDesigner/WebGL, and routing audio through an interface; which I am currently parking in the middle of development at the moment. As each tool requires stiff learning curve, I am not sure when the prototype would be released at the moment though.